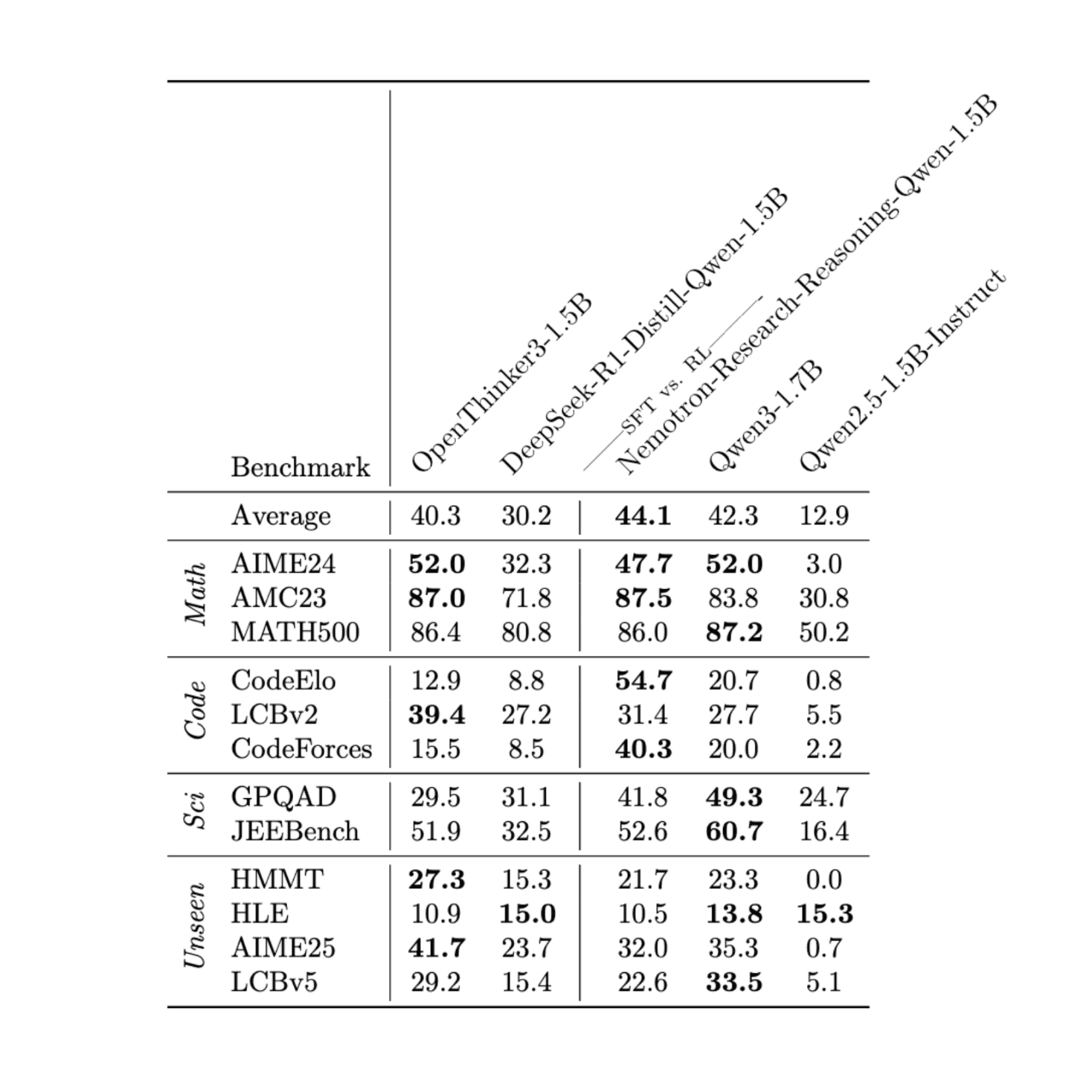
We are releasing OpenThinker3-1.5B, a new lightweight model fine-tuned from Qwen2.5-1.5B-Instruct using our OpenThoughts3-1.2M dataset. OpenThinker3-1.5B is the top-performing SFT-only model at its size, outperforming R1-Distill-1.5B by an average of 10.1 points across various math, code, and science datasets. Its compact size results in significantly lower memory requirements, enabling faster training and inference. This makes it ideal for quick experimentation in resource-constrained environments, deployment on edge devices, and RL for reasoning research.
Data Composition
To train OpenThinker3-1.5B, we gathered math, code, and science questions from various sources and filtered them through a comprehensive data pipeline. This pipeline involved several steps, including source mixing, question filtering, and generating multiple answers. We then scaled up this pipeline to reach 1.2M question-answer samples. See our OpenThoughts paper for full details on how we constructed the OpenThoughts3-1.2M dataset.

Model Performance
Our model significantly outperforms existing models such as R1-Distill-1.5B. Moreover, the model is only two points worse than Qwen3-1.7B, a closed-data model from a frontier lab. Furthermore, we achieve SOTA on several benchmarks at this model scale, including AIME24, AMC23, LiveCodeBenchv2, HMMT, and AIME25. We also highlight that the excellent Nemotron model from Nvidia is powerful, especially on CodeElo and CodeForces.
To achieve this performance, we conducted a hyperparameter sweep to identify a strong set of hyperparameters at the 1.5B scale. We found that the model benefited from a higher learning rate and could be trained for a larger number of epochs before saturation. Our full set of hyperparameters can be found in the HuggingFace model card.
We are looking forward to seeing what the community builds with OpenThinker3-1.5B!