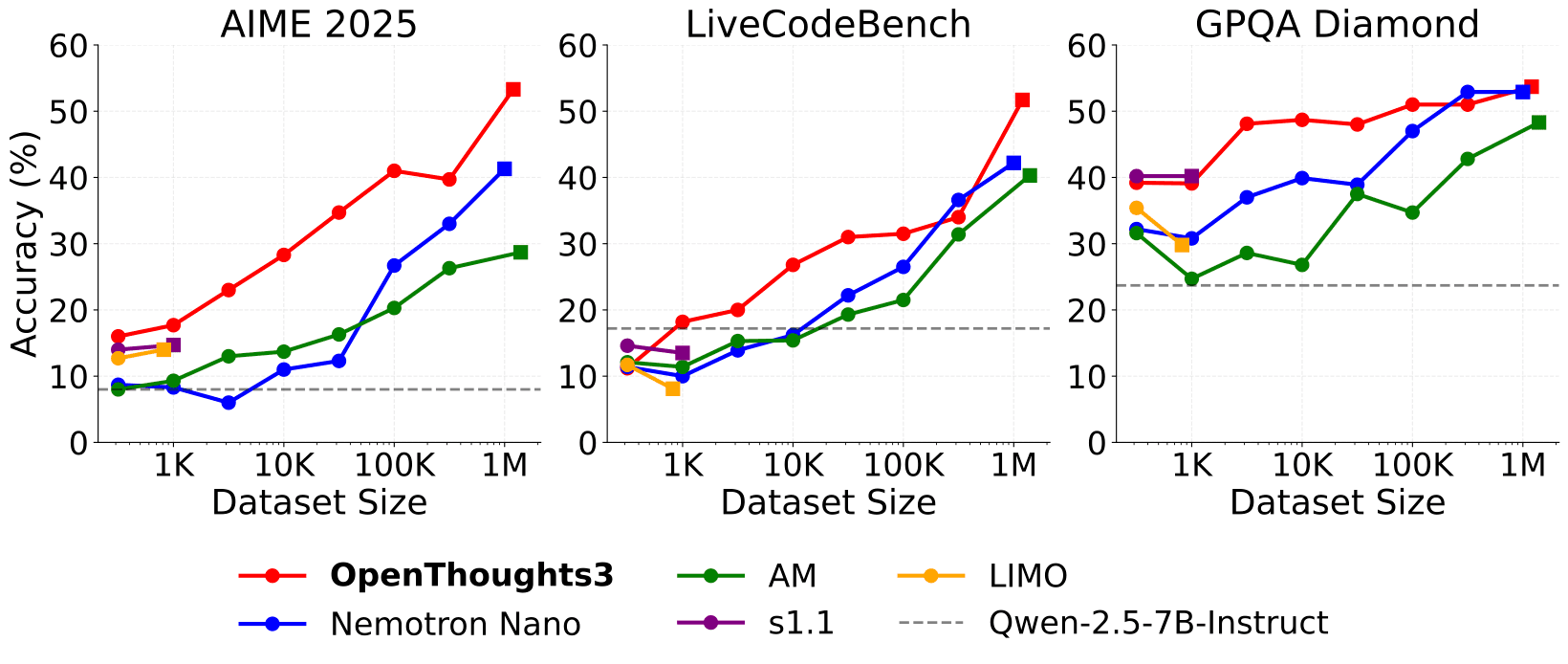
OpenThinker3-7B is the SOTA open-data reasoning model at its scale. Our model achieves 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond, representing improvements of 15.3, 17.2, and 20.5 percentage points compared to DeepSeek-R1-Distill-Qwen-7B.
All of our datasets and models are available on Hugging Face. We trained OpenThinker3-7B using only supervised fine-tuning, without any reinforcement learning. The key to our model’s performance is our new dataset, OpenThoughts3-1.2M. This dataset comprises 1.2 million questions across math, code, and science domains, with reasoning traces annotated from QwQ-32B. OpenThoughts3-1.2M is the result of over 1,000+ rigorous experiments on each stage in the reasoning dataset construction pipeline.
In the above table, we bold values within two standard errors of the highest-scoring model.
Our detailed report and experimental artifacts are fully public for the community to build upon together:
- ✨ArXiv Paper
- ✨Model Weights
- ✨Dataset
- OpenThoughts Repo - data code
- Evalchemy Repo - evaluation code
OpenThoughts3 Data Recipe
We extensively studied the effect of the following steps in our data generation pipeline:
- Question sourcing
- Question mixing
- Question filtering
- Generating multiple answers per question
- Answer filtering
- Teacher model selection

We build our pipeline iteratively, ablating the initial steps first and keeping the best choices fixed throughout the remaining ablations. Our ablations contain over 1,000 controlled experiments across three data domains: math, code, and science.
Our state-of-the-art performance is driven by the insights uncovered during the experimental pipeline. These insights include:
-
Sampling multiple answers per question from a teacher model is an effective technique to increase the size of a data source by at least 16x.
-
Models with better performance are not necessarily better teachers. QwQ-32B is a stronger teacher than DeepSeek-R1, although it scores lower on target reasoning benchmarks such as JEEBench.
-
We experimented with numerous verification and answer filtering methods, and none gave significant performance improvements.
-
Selecting questions from a small number (top 1 or 2) of high-quality sources leads to better downstream performance compared to optimizing for diversity (i.e., top 8 or 16 sources).
-
Filtering questions by LLM labeled difficulty or LLM response length yields better results than filters typical to pre-training data curation that use embeddings or fastText
Our final dataset pipeline is presented below:

Scaling Up
Scaling reasoning datasets is a powerful lever for increasing downstream performance, as we demonstrated scaling from Bespoke-Stratos-17k to OpenThoughts-114k and then again to OpenThoughts2-1M. With the stronger OpenThoughts3 data recipe, we once again take advantage of scale, scaling up to 1.2M samples consisting of 850,000 math, 250,000 code, and 100,000 science instruction and answer pairs.
We outperform the previous state-of-the-art open reasoning datasets (AM and Nemotron Nano) and clearly demonstrate that more-is-more for reasoning.
Conclusion
Our OpenThinker3-7B model and associated OpenThoughts3-1.2M are the SOTA open-data model and SFT dataset for reasoning models, respectively. Our data pipeline is built on the insights gained through rigorous and comprehensive experimentation across the entire protocol. We release all artifacts from our research and hope to fuel the research community further. We plan to further scale this pipeline up in the future and release a 32B equivalent to OpenThinker3-7B.