
OpenThoughts-Agent is a family of best-in-class open-data Qwen-3 family models. Agentic language models dramatically expand the applications of AI, yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, yielding an average accuracy of 44.8% across seven agentic benchmarks and a 3.9-percentage-point improvement over the strongest existing open-data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets across all training set sizes in compute-controlled comparisons.
Our detailed report and experimental artifacts are fully public for the community to build upon together:
OpenThoughts-Agent Data Pipeline
Our data pipeline consists of:
- Sourcing tasks for our dataset
- Mixing these sets of tasks
- Filtering out lower-quality tasks
- Using a teacher model to generate agentic rollouts for the tasks
- Filtering out lower-quality rollouts
- We also ablate choosing the best teacher model
We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. Our insights into data quality lead to large downstream agentic capabilities.
- Sourcing tasks from a diverse combination of synthetic coding problems, computer-use online forum questions, and more leads to strong general capabilities
- Filtering tasks based on the number of tokens frontier models need to solve them leads to higher quality tasks
- Filtering out agentic traces that are fewer than 5 turns also improves dataset quality
- Using synthetic task augmentation to diversify data leads to stronger models as data scale increases
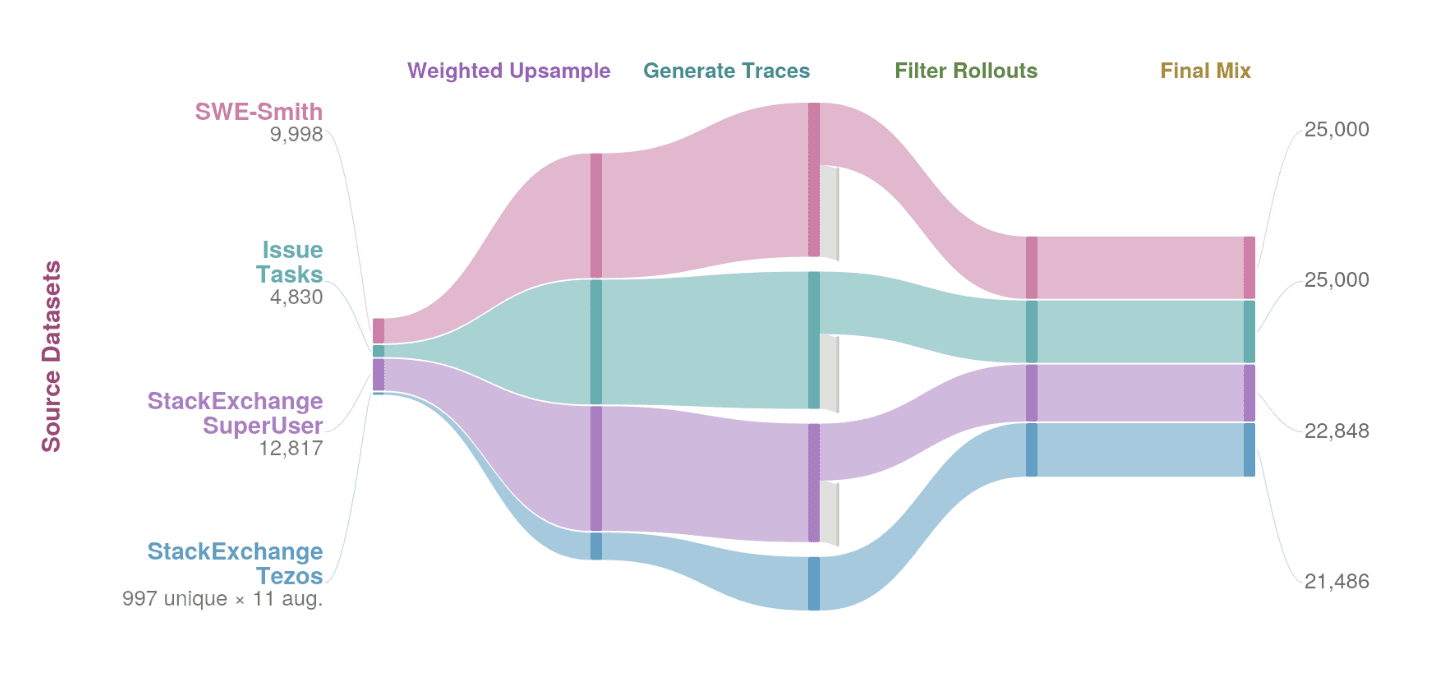
Our final pipeline is depicted below:
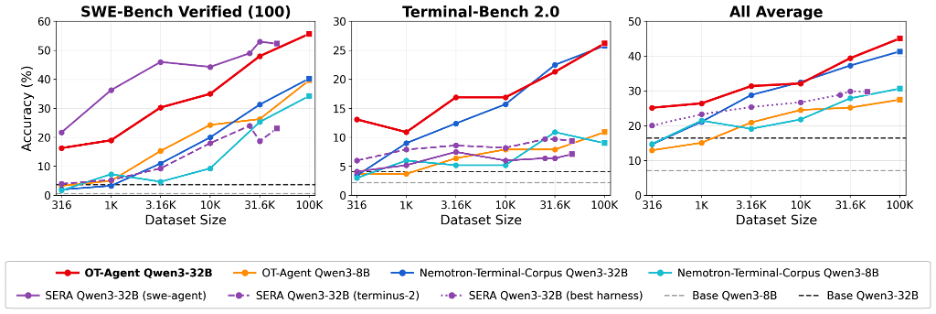
Scaling up
Dataset size is a powerful metric for improving downstream quality. Using the above insights and increasing the dataset scale to 100K, we generate the SOTA open-data 32B agentic model finetuned from the Qwen-3 family. Across dataset scales, we see our dataset is the only one competitive on both general agentic and coding capabilities.
Final SFT Results
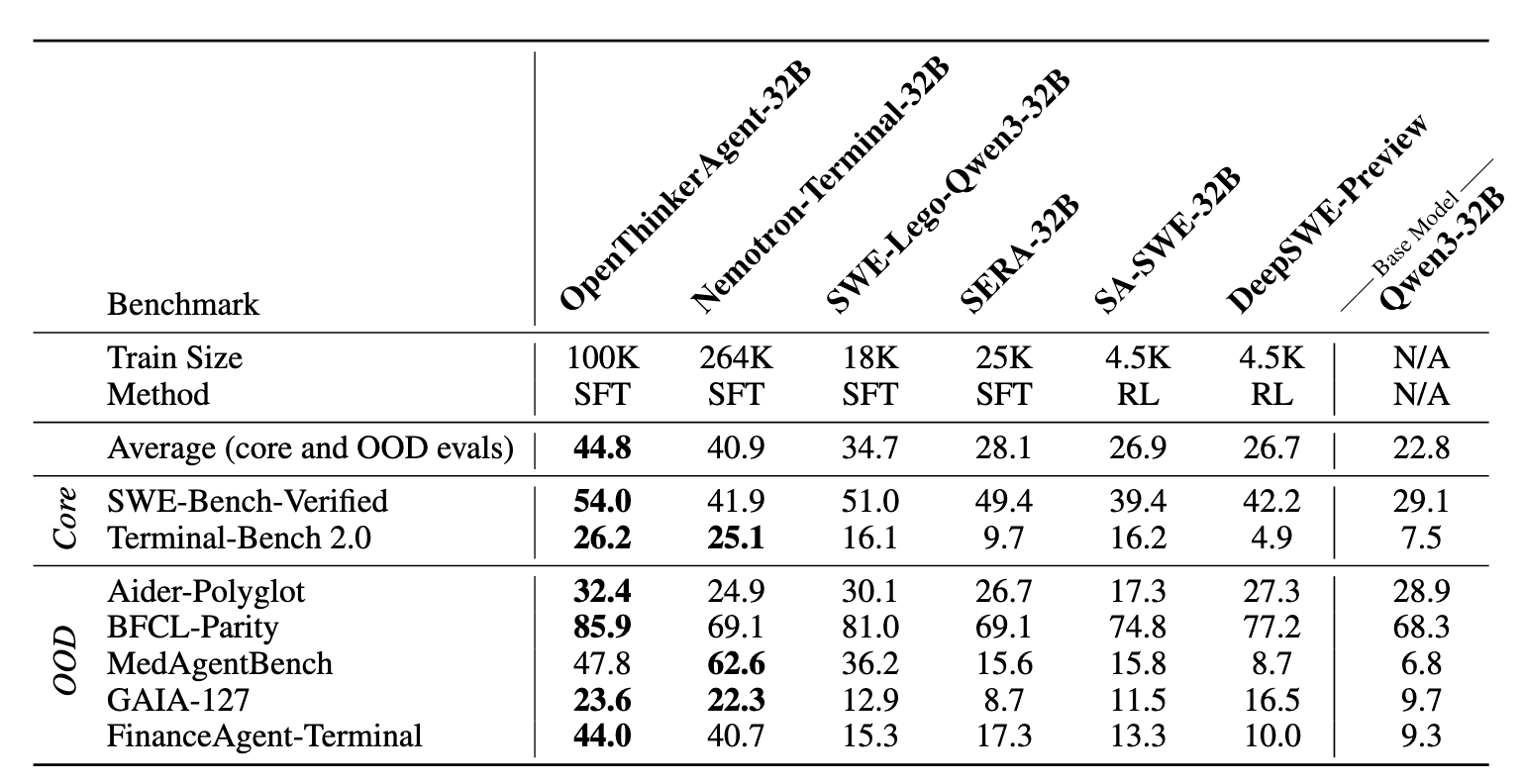
Our final model OpenThinkerAgent-32B is a strong agentic model. Not only is it good at the capabilities on core benchmarks tracked throughout our ablation, but it is also state of the art on 4 out of the 5 held-out benchmarks, including capabilities in finance, search, and multilingual code. It outperforms all existing open-data agentic models at the same model scale on average.
Reinforcement Learning
We also briefly explore sourcing tasks for RL datasets. After iterating through several RL environment generation strategies, we found pymethods2test to be the most performant. It is a mix of Codeforces / CodeChef / TopCoder style competitive-programming problems that have been re-cast as single-function Python contracts with synthesized docstring-style task descriptions and auto-generated unittest suites. Training an 8B model with a short SFT phase and RLing on this dataset yields the SOTA open-data 8B agentic model.
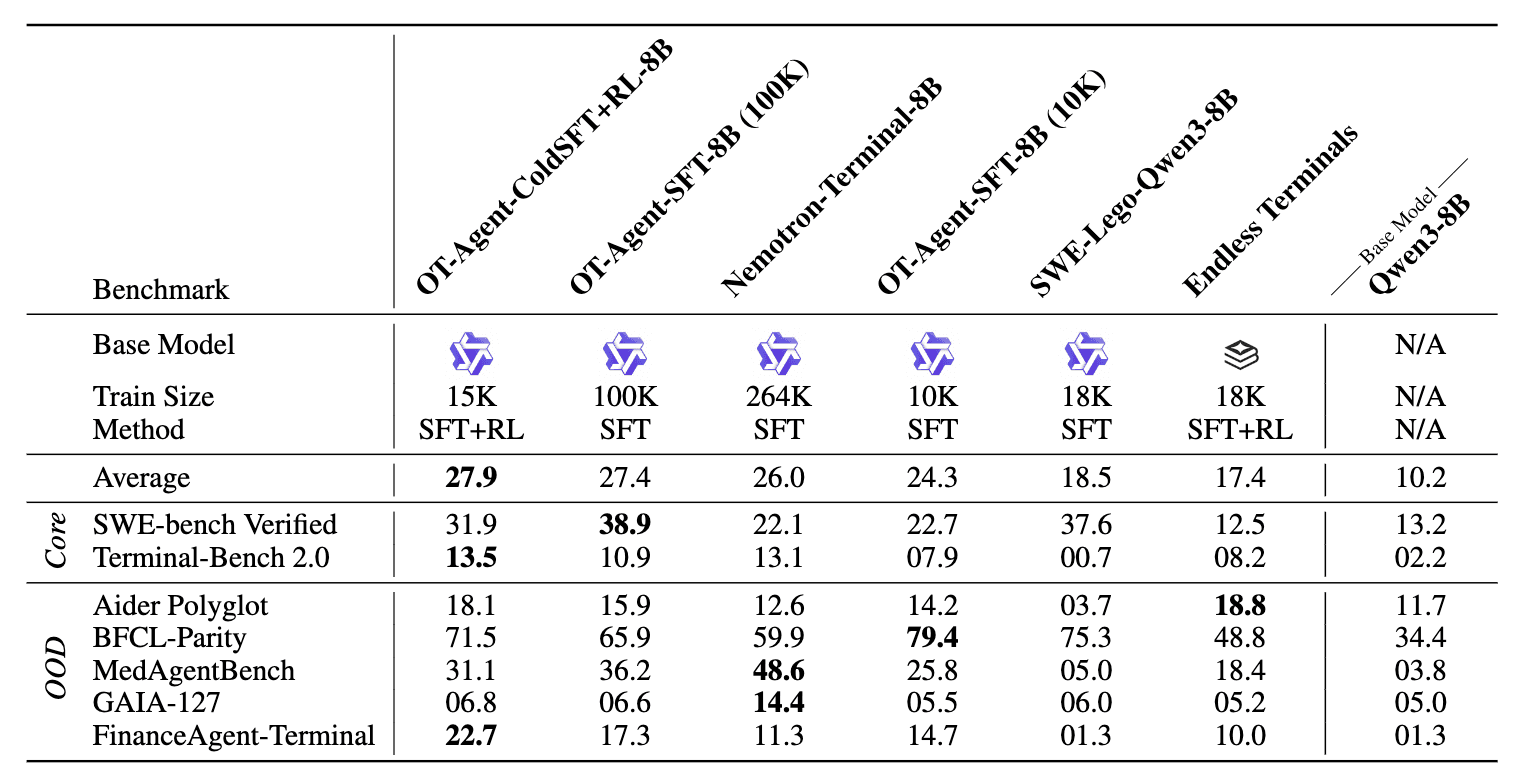
Conclusion
Our core artifact release, OpenThinker-Agent2, includes SOTA models and datasets for agentic training. We built these artifacts through over 100 careful data curation ablations. We release all these artifacts in hopes that we fuel the research community to further improve agentic capabilities of open-source models.
Citation
@misc{raoof2026openthoughtsagentdatarecipesagentic,
title={OpenThoughts-Agent: Data Recipes for Agentic Models},
author={Negin Raoof and Richard Zhuang and Marianna Nezhurina and Etash Guha and Atula Tejaswi and Ryan Marten and Charlie F. Ruan and Tyler Griggs and Alexander Glenn Shaw and Hritik Bansal and E. Kelly Buchanan and Artem Gazizov and Reinhard Heckel and Chinmay Hegde and Sankalp Jajee and Daanish Khazi and Emmanouil Koukoumidis and Xiangyi Li and Hange Liu and Shlok Natarajan and Harsh Raj and Nicholas Roberts and Ethan Shen and Nishad Singhi and Michael Siu and Ashima Suvarna and Hanwen Xing and Patrick Yubeaton and Robert Zhang and Leon Liangyu Chen and Xiaokun Chen and Steven Dillmann and Saadia Gabriel and Xunyi Jiang and Anurag Kashyap and Boxuan Li and Yein Park and Minh Pham and Sujay Sanghavi and Lin Shi and Ke Sun and Yixin Wang and Zhiwei Xu and Erica Zhang and Siyan Zhao and Wanjia Zhao and Jenia Jitsev and Alex Dimakis and Benjamin Feuer and Ludwig Schmidt},
year={2026},
eprint={2606.24855},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.24855},
}